Bert Wesley Huffman Wife - Exploring BERT's Language Power
When people talk about significant shifts in how we understand language, there's one name that, you know, often comes up in conversation: BERT. It’s a pretty big deal in the world of language technology, actually, and has truly changed the way computers process and make sense of human communication. This particular innovation, you see, has had a profound influence on everything from search engines to how virtual assistants respond to our questions, so it's almost everywhere now.
This powerful system, which Google first brought into the light back in 2018, really did something different. Before it arrived, getting a computer to grasp the subtle meanings in words, especially when those words popped up in different contexts, was, well, a bit of a puzzle. BERT, however, introduced a completely new way of looking at language, allowing digital brains to consider the whole picture, not just individual pieces. It's like, imagine trying to understand a joke by only hearing one word; BERT helps the computer hear the whole setup and punchline.
So, while you might be wondering about someone like, say, a 'bert wesley huffman wife' and their story, our focus here is actually on a different kind of impactful entity: the BERT model itself. This article will peel back the layers on this groundbreaking technology, exploring its origins, how it functions, and why it has become such a central figure in the ongoing evolution of artificial intelligence and language comprehension. We'll look at what makes it tick, and just how much it has shaped our digital interactions.
- Two Babies One Fox X
- Aishah Sofey Onlyfans Leaked
- Aisah Sofey Leaked
- Iran Economy 2024
- Christopher Walken Net Worth
Table of Contents
- The Dawn of a New Era - What is BERT?
- How Does BERT Actually Work?
- What Made BERT So Different?
- BERT's Bidirectional Approach: What Does it Mean for 'bert wesley huffman wife' Search?
- BERT's Architecture - A Closer Look
- What Were BERT's Early Achievements?
- Beyond the Basics - Fine-Tuning BERT: How it Handles Queries like 'bert wesley huffman wife'?
- The Lasting Legacy of BERT
The Dawn of a New Era - What is BERT?
Back in 2018, a pretty significant moment occurred in the world of digital language processing, actually. Google AI, a team of rather clever folks, introduced something they called BERT. This wasn't just another small step; it was, you know, a really big leap forward for how computers could interact with and understand human language. At its heart, BERT is an open-source machine learning framework, sort of like a powerful toolkit, that was specifically put together for natural language processing, or NLP as it's often called. It was, in some respects, a true turning point.
Before BERT came along, a lot of the ways computers tried to understand sentences were, well, a little bit one-sided. They might read from left to right, or perhaps from right to left, but they didn't really take everything in at once. BERT, however, brought a genuinely new perspective to the table. It was built using a special part of a larger system called a Transformer, specifically the 'encoder' side. This meant it could look at all the words in a sentence at the same time, giving it a much richer, more complete picture of what was being said. It’s like, you know, getting the full story instead of just half of it.
So, to put it simply, BERT stands for Bidirectional Encoder Representations from Transformers. That's a bit of a mouthful, but what it really means is that this system can read and process language in both directions simultaneously, which was a huge deal. It wasn't like older methods, say, like Bi-LSTMs, which would process things in two separate passes. BERT just takes it all in, all at once, giving it a far more nuanced grasp of context. This capability, in fact, changed everything for how machines could learn about words and their meanings within sentences.
- Neuro Gum Net Worth
- Iran New Currency
- Selena Quintanilla Outfits A Timeless Fashion Legacy
- Ifsa Sotwe Turk
- Sotwe T%C3%BCrkk
How Does BERT Actually Work?
At its core, BERT operates on a rather fascinating principle, you know, called the self-attention mechanism. Think of it like this: when BERT is trying to figure out the meaning of a single word in a sentence, it doesn't just look at that word in isolation. Instead, it pays very close attention to all the other words around it, both before and after. This simultaneous consideration of its surroundings is what gives it that 'bidirectional' superpower. It’s almost as if every word is whispering secrets to every other word, and BERT is listening to all of them at once to get the full story.
This means that when it's encoding a particular piece of language, it's actually using the entire context of the sentence to shape its understanding. For example, the word "bank" can mean a financial institution or the side of a river, right? Older systems might struggle to tell the difference without a lot of extra help. But BERT, because it considers all the surrounding words, can pretty easily figure out if you're talking about depositing money or going fishing. It’s a genuinely clever way to approach the often tricky business of language.
The whole process, in fact, involves a few distinct parts working together. At a really high level, BERT is made up of, like, four main modules. One of these, for instance, is responsible for taking regular English text and turning it into a sequence of numbers, or 'tokens' as they're often called. This is sort of like translating human words into a language that computers can understand, a fundamental first step in getting any kind of digital language processing going. This initial conversion is, you know, pretty vital for everything that follows.
What Made BERT So Different?
Well, to be honest, a lot of what made BERT stand out was its ability to truly grasp the meaning of words based on their surroundings. Before BERT, many language models would assign a single, unchanging numerical representation, a 'word vector,' to a word, regardless of where it appeared. For instance, the word "water" would have the same vector whether you were talking about "plants needing water" or "financial statements having water" (meaning, you know, something a bit fishy). This meant those older models often missed the subtle differences in meaning that context provides.
BERT, on the other hand, was built to be much more sensitive to these nuances. It would provide a different word vector for "water" depending on the sentence it was in. So, the representation of "water" in "plants need to absorb water" would be, like, completely different from its representation in "there's water in the financial report." This adaptability, this understanding that words shift their meaning based on their companions, was a pretty big deal and truly set it apart from its predecessors. It was a step towards machines truly understanding language as humans do, in a way.
This context-aware approach, you see, allowed BERT to capture a far richer and more accurate sense of meaning. It wasn't just memorizing definitions; it was learning how words interacted with each other, how they influenced each other's meaning. This kind of deep contextual understanding was, in fact, a revolutionary concept for the time and quickly showed its worth in various language tasks. It meant that the model could, more or less, reason about language in a much more human-like fashion.
BERT's Bidirectional Approach: What Does it Mean for 'bert wesley huffman wife' Search?
When we consider BERT's bidirectional approach, it really opens up possibilities for how computers handle all sorts of language, including specific queries. So, what does this mean, you know, for something like a search for 'bert wesley huffman wife'? Basically, it means that when you type that phrase into a search engine powered by BERT, the system doesn't just look at each word individually. It takes the entire phrase, 'bert wesley huffman wife,' as a complete unit.
This allows the system to understand the relationships between "bert," "wesley," "huffman," and "wife" all at once, rather than processing them in a linear, step-by-step fashion. It can, in some respects, grasp the intent behind the full query. For example, if you were searching for "apple pie recipe," BERT wouldn't just look for "apple" and "pie" separately; it would understand that you're looking for a recipe for a specific dish. Similarly, for a phrase like 'bert wesley huffman wife,' it tries to understand the collective meaning and intent of the whole string of words.
This comprehensive understanding is pretty crucial for delivering relevant search results. Without a bidirectional approach, a search engine might, you know, struggle to differentiate between "bert" as a name, "wesley" as a name, "huffman" as a surname, and "wife" as a relationship, if it just looked at them one after another. BERT's ability to see the whole picture helps it to connect these individual pieces into a coherent query, allowing it to find information that is genuinely related to the entire phrase 'bert wesley huffman wife', rather than just fragments. It's about getting the full context, actually.
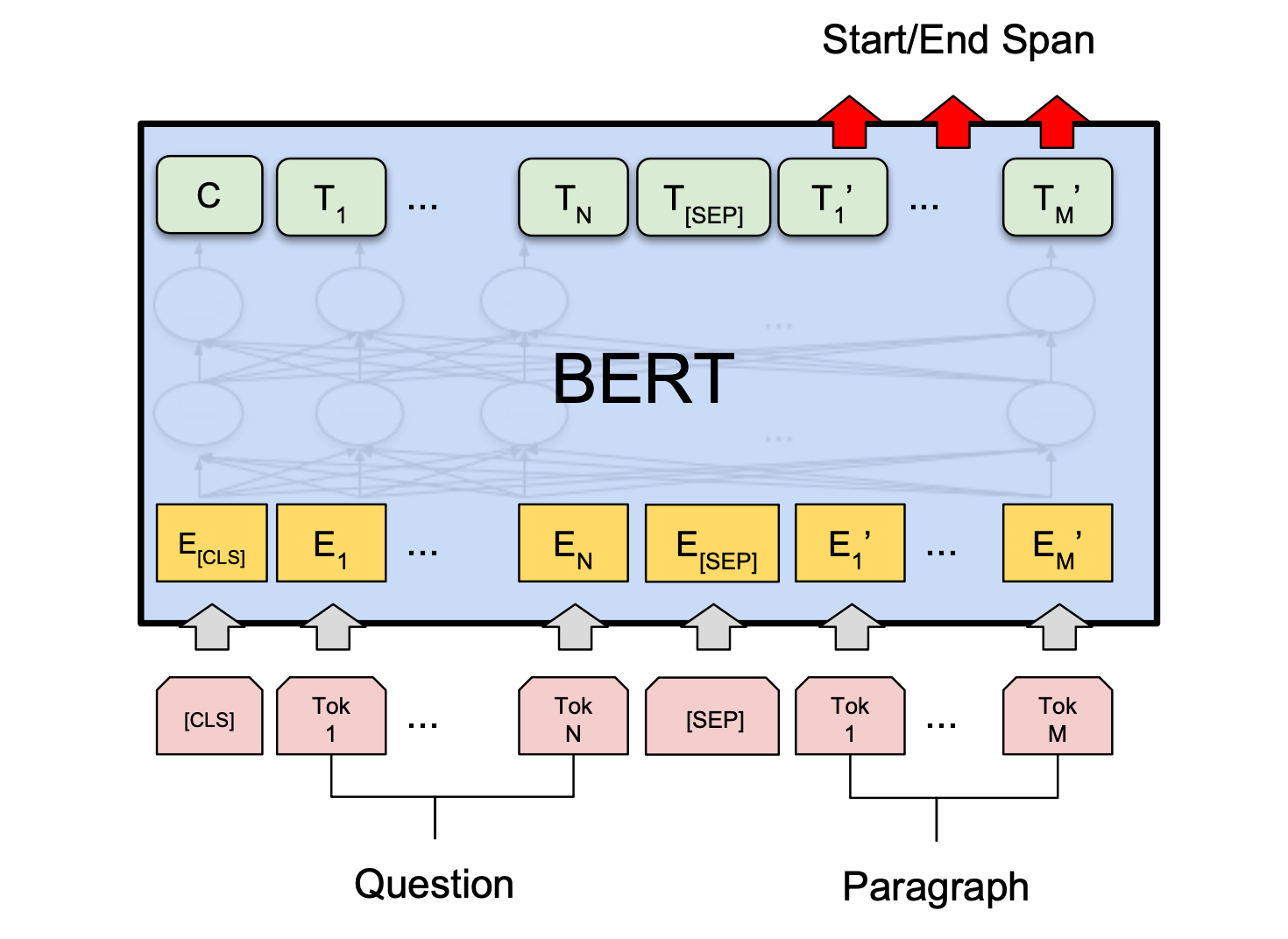
BERT's Architecture - A Closer Look
The core design of BERT, you know, is surprisingly straightforward, yet it's incredibly effective at what it does. Its architecture, while simple in its foundational concept, is sufficiently capable of handling a wide array of tasks in natural language understanding. It's one of the first and most prominent applications of the Transformer model in the field of natural language processing, setting a precedent for many models that have come after it. This simplicity, in a way, is part of its genius.
The genius of BERT's unified architecture is that it allows the model to adapt to various downstream tasks with very minimal modifications. This means that once BERT has been extensively trained on a huge amount of text data, it can then be fine-tuned, or slightly adjusted, for a whole host of specific language-related jobs without needing a complete overhaul. This makes it a really versatile and highly effective tool in natural language understanding, which is, you know, quite a big advantage.
The initial training process for BERT is, in fact, quite involved. It typically goes through a few key stages. First, there's the tokenization process, which is, basically, converting all the text into those numerical 'tokens' we talked about earlier. Then,


Detail Author:
- Name : Kennith Langworth
- Username : tmarvin
- Email : metz.camron@monahan.com
- Birthdate : 1978-08-12
- Address : 4646 Forrest Ramp Suite 073 Labadiefort, OR 28396
- Phone : +1-440-661-3567
- Company : Wolf Ltd
- Job : Utility Meter Reader
- Bio : Autem voluptatem ullam non voluptatem nisi nemo. In quod eos alias officia impedit. Tempore odio quasi eum odio quos adipisci nostrum unde. Ullam vel vitae rem cumque eaque.
Socials
tiktok:
- url : https://tiktok.com/@kemmer2003
- username : kemmer2003
- bio : Quo omnis nihil ipsum. Ut eligendi ut vitae et consequatur eius.
- followers : 6695
- following : 550
twitter:
- url : https://twitter.com/yadira_xx
- username : yadira_xx
- bio : Quam quos dolores sequi consequatur totam exercitationem quia. Dicta fugit est porro dolorem voluptatem. Eveniet laudantium ipsam impedit corrupti culpa.
- followers : 1270
- following : 2958
instagram:
- url : https://instagram.com/yadira_xx
- username : yadira_xx
- bio : Voluptatem culpa sed tenetur. Commodi aut qui assumenda molestiae. Ipsa dolor qui ut delectus.
- followers : 3580
- following : 1529

{kind=link}